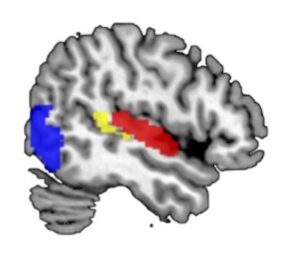
 We are constantly bombarded with information from different sensory modalities (vision, audition, taste etc.) and early processing of this information is computed independently from the other modalities in primary and secondary association cortices. Only later, the different sensory streams are integrated into a coherent multi-modal percept. Such cross-modal integration is often computed in the TPJ and the posterior part of the superior temporal sulcus (postSTS).
We are constantly bombarded with information from different sensory modalities (vision, audition, taste etc.) and early processing of this information is computed independently from the other modalities in primary and secondary association cortices. Only later, the different sensory streams are integrated into a coherent multi-modal percept. Such cross-modal integration is often computed in the TPJ and the posterior part of the superior temporal sulcus (postSTS).
The information of different sensory streams may predict reward or punishment to a different degree and this predictive information could influence the integration of these modalities. In this project, we are investigating how the representations in these brain regions that underlie cross modal integration change as a function of reward learning.
In a first study, Christoph Korn used bimodal congruent stimuli and associated one of the modalities
(visual, auditory) with a monetary reward, but not the other. 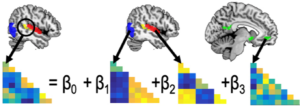 We then tested with representational similarity analyses (Kriegeskorte, Front Hum Neurosci, 2008) and pattern component modeling (LINK TO Diedrichsen, NIMG, XXXX) which unimodal information from sensory cortices (vision: LOC, audition: A1) predicted the integrated information in TPJ. We found that both regions and the reward representations in vmPFC contributed to the integrated representation, but that it was dominated by the auditory information. Furthermore, we also found that crossmodal representations became more similar after learning,
We then tested with representational similarity analyses (Kriegeskorte, Front Hum Neurosci, 2008) and pattern component modeling (LINK TO Diedrichsen, NIMG, XXXX) which unimodal information from sensory cortices (vision: LOC, audition: A1) predicted the integrated information in TPJ. We found that both regions and the reward representations in vmPFC contributed to the integrated representation, but that it was dominated by the auditory information. Furthermore, we also found that crossmodal representations became more similar after learning,
when they involved the rewarded modality.
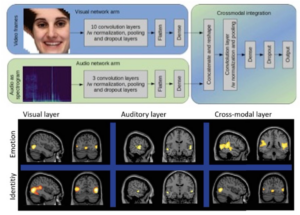 RSA is a very general analysis framework that not only allows comparisons of neural activation to different stimuli and conditions in the same brain, but also enables the comparison between brain activation patterns and layer activity in a deep learning network. Christoph Korn used this framework to compare the fMRI patterns to short videos depicting different actors saying sentences with different emotional tones to layer weights in supervised deep learning network that processes visual stimuli (the images in the videos) and auditory stimuli (the emotional speech) in spearpate pathways akin to what we know about distinct unimodal processing in the brain. These RSA analyses revealed that unimodal and multimodal brain regions correlated with layers from the respective arm of the network.
RSA is a very general analysis framework that not only allows comparisons of neural activation to different stimuli and conditions in the same brain, but also enables the comparison between brain activation patterns and layer activity in a deep learning network. Christoph Korn used this framework to compare the fMRI patterns to short videos depicting different actors saying sentences with different emotional tones to layer weights in supervised deep learning network that processes visual stimuli (the images in the videos) and auditory stimuli (the emotional speech) in spearpate pathways akin to what we know about distinct unimodal processing in the brain. These RSA analyses revealed that unimodal and multimodal brain regions correlated with layers from the respective arm of the network.
In a second study Sasa Redzepovic (LINK TO People/Alumni/Sasa) used a cross-modal second-order conditioning paradigm to test whether the learning effects can also be observed for secondary stimuli that were never directly associated with a reward. Pupillary dilation responses and skin conductance responses (LINK To Methods/Psychophysiology) show strong signs of first-order conditioning (direct association of stimuli with an aversive event), but the secondary associations were rather weak, possibly due to differences in the responses prior the conditioning procedure.
 In an behavioral study Julia Splicke-Liss (LINK TO People/Alumni/Julia) also looked at the interfering role of semantic congruency onto top-down (endogenous) attention. Participants evaluated the semantic congruency of two stimuli in the attentional focus, while a third stimulus was also presented (Splicke-Liss et al., 2019). When this third stimulus was incongruent with the other, they committed more errors. Computational modeling using the drift diffusion model revealed an attenuated drift rate, which ws like due to the interfering effect of the incongruent thirst stimulus. Interestingly, this effect occurred irrespective of stimulus modality suggesting a more general role of how semantic congruence interferes with attentional selection.
In an behavioral study Julia Splicke-Liss (LINK TO People/Alumni/Julia) also looked at the interfering role of semantic congruency onto top-down (endogenous) attention. Participants evaluated the semantic congruency of two stimuli in the attentional focus, while a third stimulus was also presented (Splicke-Liss et al., 2019). When this third stimulus was incongruent with the other, they committed more errors. Computational modeling using the drift diffusion model revealed an attenuated drift rate, which ws like due to the interfering effect of the incongruent thirst stimulus. Interestingly, this effect occurred irrespective of stimulus modality suggesting a more general role of how semantic congruence interferes with attentional selection.